词法分析是编译过程中的第一步,如果您还不了解 PL/0 编译系统的整体结构,请先查看PL/0 简单编译系统:(零) 综述。
词法分析要做什么
词法分析要做的是: 把源程序中字符识别成一个个的单词 (Token)。
单词包括:
- 保留字 (
iffor等) - 标识符(
变量名函数名等) - 常数 (
120.231TURE等) - 分界符或操作符 (
+-*/等)
比如对于 c 语言的一段源程序:
int a = 0, 词法分析就会识别出保留字int, 标识符a,操作符=, 常数0。
单词分析
从PL/0 语言文法的 EBNF 表示中可以看出:
保留字有:
const var procedure odd if then else while do call begin end repeat until read write
共 16 个。
标识符组成:
<标识符> ::= < 字母 >{< 字母 >|< 数字 >}
常数中只有无符号整数:
<无符号整数> ::= < 数字 >{< 数字 >}
分界符或操作符有:
. , ; = := + - ( ) * / <> < <= > >=
共 17 个。
采用保留字和分界符一符一类的方法,也就是每个保留字和分界符都分成一类,而不是所有的保留字一类,所有的分界符一类。
所以一共有 16 + 1 + 1 + 17 = 35 类单词。
建立 Symbol 类,并填入单词,具体代码可参看 github 完成单词分类。
每个单词应记录什么?
前面所说的只是单词的所有类别,但对于每一个具体的单词Symbol symbol = new Symbol(),应该要记录下什么信息?
- 对于每一个 Symbol,必须要有一个 Symbol 的类型,也就是前面所说的 35 种类型中的一种。
- 对于类型是保留字的,除了标记为保留字之外,还要记录这个保留字的名称。
- 对于类型是数字的,除了要知道它的类型是数字外,还要记录下这个数字的值。
所以对于每个 Symbol 设置下面三个属性:
private int symbolType; // 符号的类型,即前面35种中的一种
private int number = 0; // 如果符号是无符号整数,则记录其值
private String name = ""; // 如果符号是保留字,则记录其名字
public Symbol(int symbolType) {
this.symbolType = symbolType;
}对于number 和 name 还要有 setter 来设置他们的值:
/*------------------------------
* Setter
* -----------------------------
*/
public void setNumber(int number) {
this.number = number;
}
public void setName(String name) {
this.name = name;
}具体可参看 github 每个具体单词应有的属性
开始
整体过程:通过 getChar() 方法获取一个字符,然后依据字符的类型分别进入不同的子程序处理,最后得到一个单词。
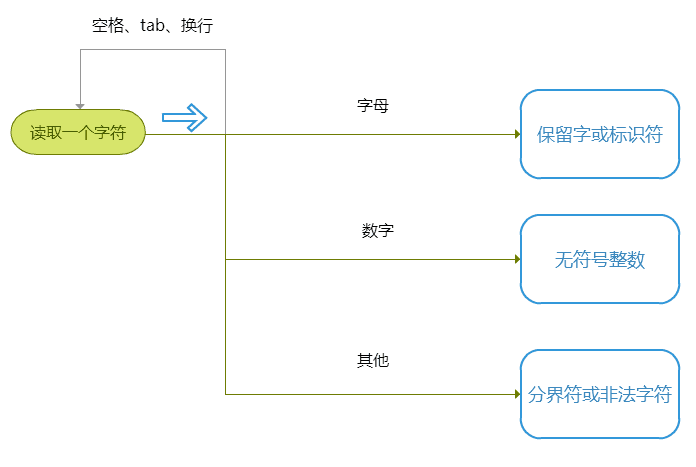
getChar()
getChar()是读取一个字符。而源代码是从文件中读取,为了增大磁盘 IO,每次读取一整行,而不是每次读取一个字符。其中,为了方便和效率,做了以下变动:
- 如果读取的一行是空行,则跳过。
- 把读取的一行中的所有
tab符替换成空格。 - 因为每次读取的是一行,直接跳过了
换行符,所以在读取的一行末尾添加一个空格代替换行符。
具体实现可参看 github 完成读取一个字符
所以,调整后的流程为:
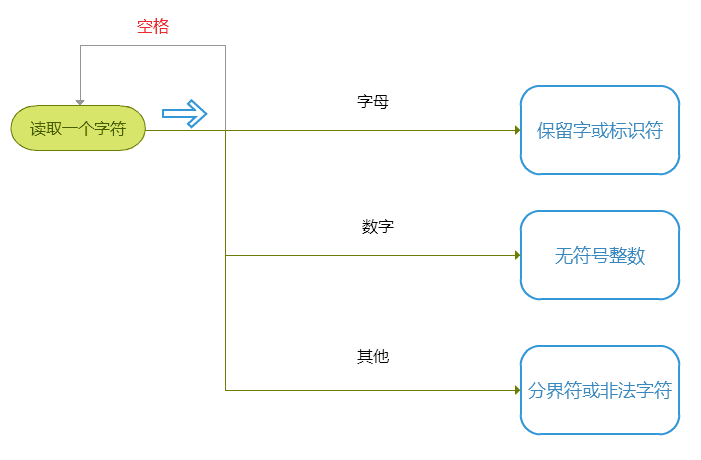
所以词法法分析中获取一个单词的主要流程如下:(getKeywordOrIdentifier() getNumber() getOperator()将在下面逐步介绍。)
/**
* 词法分析中获取一个单词
*
* @return Symbol
*/
public Symbol getSymbol() {
// 每次都提前读取一个字符
// 跳过空格
while (isSpace()) {
getChar();
}
if (isLetter()) {
// 保留字或者标识符
return getKeywordOrIdentifier();
} else if (isDigit()) {
// 无符号整数
return getNumber();
} else {
// 分界符 或者 非法字符
return getOperator();
}
}具体实现可参看 github 词法分析的主要过程
注意:
词法分析中每进入一个流程时都会提前读取一个字符。所以
getSymbol()函数中一开始不需要调用getChar()来读取一个字符。下面将会再次提及。
识别保留字和标识符
识别过程主要是以下两个步骤:
- 首先要把字符拼接成字符串
token。 - 在保留字列表中查找
token是否存在,如果存在,说明是保留字,否则为标识符。
步骤 1 很简单:
String token = ""; // 识别的单词
// 将字符拼接成字符串
while (isLetter() || isDigit()) {
token += currentChar;
getChar();
}在步骤 2 中,必须要建立保留字列表。而为了提高查找效率,使用二分查找。所以保留字按字母顺序排列。
所以在Symbol.java中添加以下内容:
// 设置保留字名字,按照字母顺序,便于二分查找
public static final String[] WORD = new String[] {
"begin", "call", "const", "do",
"else", "end", "if", "odd",
"procedure", "read", "repeat", "then",
"until", "var", "while", "write"
};
// 保留字对应的符号值
public static final int[] WORD_SYMBOL = new int[] {
BEGIN_SYMBOL, CALL_SYMBOL, CONST_SYMBOL, DO_SYMBOL,
ELSE_SYMBOL, END_SYMBOL, IF_SYMBOL, ODD_SYMBOL,
PROCEDURE_SYMBOL, READ_SYMBOL, REPEAT_SYMBOL, THEN_SYMBOL,
UNTIL_SYMBOL, VAR_SYMBOL, WHILE_SYMBOL, WRITE_SYMBOL
};识别过程如下:
// 二分查找保留字
int index = Arrays.binarySearch(Symbol.WORD, token);
if (index < 0) { // 未在保留字数组中找到token,说明token是标识符
symbol = new Symbol(Symbol.IDENTIFIER);
symbol.setName(token);
} else { // 在保留字数组中找到token,说明token是保留字
symbol = new Symbol(Symbol.WORD_SYMBOL[index]);
}具体代码可参看 github 识别保留字和标识符
识别无符号整数
识别无符号整数很简单,只要将数值计算出来然后记录即可。
在数值的计算上,如果先读取了数字2,则另value = 2,此时又读取了一个5,也就是25,则只要另value = value * 10 + 5 = 2 * 10 + 5 = 25即可,以此类推。具体实现如下:
int value = 0;
do {
value = value * 10 + (currentChar - '0'); // 计算无符号整数的值
getChar();
} while (isDigit());具体代码可参看 github 识别无符号整数
注意:
在识别保留字和标识符和识别无符号整数结束前都使用
getChar()提前读取下一个字符
识别分界符
在读取到分界符时,如果读取的是+,则只可能是加法运算符 (Symbol.PLUS);而如果读取到<,则有可能是<,也有可能是<=,所以对于第二中应特别考虑。
应特别考虑的字符有:
:=(当:后面一个字符不是=时出错)<、<=和<>>和>=
对于此类两个字符的分界符,也只要查看下一个字符就能判断类型。而词法分析都会提前读取下一个字符,实现起来很简单。例如对于 2:
switch(currentChar) {
case '<':
getChar();
switch (currentChar) {
case '>': // 不等于 <>
symbol = new Symbol(Symbol.NOT_EQUAL);
getChar();
break;
case '=': // 小于等于 <=
symbol = new Symbol(Symbol.LESS_OR_EQUAL);
getChar();
break;
default: // 小于
symbol = new Symbol(Symbol.LESS);
break;
}
break;
}除了以上几种分界符外,还可能是一些简单的分界符或者是不可识别的符号。
而对于不可识别的字符,都用NULL(也就是Symbol.NUL)来表示。
对于这些字符,使用switch语句一一列出的话会显得十分繁琐。这里使用了一个数组simpleOperators来记录这些简单字符和不可识别的符号。如下所示:
simpleOperators = new int[256]; // 因为char的范围是[0, 255],所以数组大小最大只需256
Arrays.fill(simpleOperators, Symbol.NUL); // 对于其他不可识别的字符,全都设置为[NULL]
simpleOperators['.'] = Symbol.PERIOD;
simpleOperators[','] = Symbol.COMMA;
simpleOperators[';'] = Symbol.SEMICOLON;
simpleOperators['='] = Symbol.EQUAL;
simpleOperators['+'] = Symbol.PLUS;
simpleOperators['-'] = Symbol.MINUS;
simpleOperators['('] = Symbol.LEFT_PARENTHESIS;
simpleOperators[')'] = Symbol.RIGHT_PARENTHESIS;
simpleOperators['*'] = Symbol.MULTIPLY;
simpleOperators['/'] = Symbol.DIVIDE;使用了simpleOperators之后,只要symbol = new Symbol(simpleOperators[currentChar]);就能正确的识别单词了。
具体代码可参看 github 识别分界符
下一步做什么
在综述中分析了整个编译过程:

下一步将会开始使用递归下降子程序法编写语法分析程序。从图中可以看出,语法分析程序是整个编译过程的核心,这一节中的词法分析将会作为一个子程序被语法分析调用,然后做下一步的编译工作。
参考资料:
[1] 张莉, 杨海燕, 史晓华等. 编译原理及编译程序构造[M]. 清华大学出版社, 2011:307-327.
[2] jiangnan314 编译实践 - PL/0 编译系统实现